Coherent 400G ZR+ — When Lead Time Becomes a Design Problem
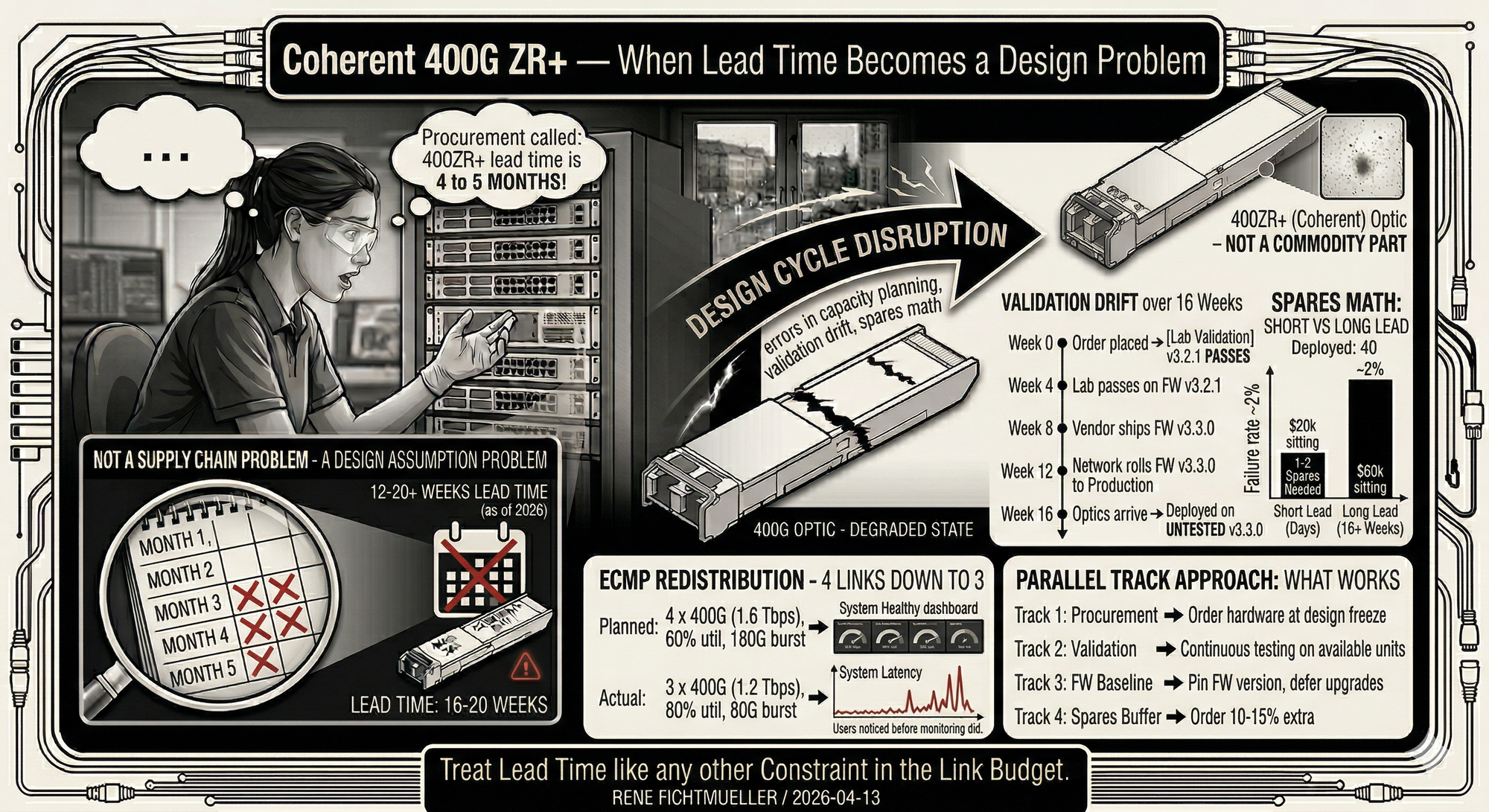
The design is complete. Procurement comes back: 400ZR+ optics are not available for four to five months. That is not a supply chain problem. It is a design assumption problem.
The design is done. Topology fixed, spans verified, optical budgets calculated, platform compatibility validated. Engineering has signed off. Nothing blocking deployment.
Then procurement calls: 400ZR+ optics won't ship for four to five months.
Most teams file this under "supply chain." It belongs under "design assumptions." Coherent optics got treated like commodity parts. They are not commodity parts.
Modulation DP-16QAM (coherent)
Form Factor QSFP-DD or OSFP
Reach (400ZR) up to ~120 km point-to-point
Reach (ZR+) 300–2,000+ km with amplification
DWDM Grid 75 GHz C-band, up to 64 channels
Power Draw 15–25W per module
DSP Vendor Acacia (Cisco), Inphi (Marvell), or Qualcomm
Typical Lead Time 12–20+ weeks (as of 2026)
Each module packs a full coherent DSP, laser, modulator, and receiver into a pluggable. The silicon comes from a handful of foundries. Indium phosphide laser supply is even tighter.
When a 10G SFP+ goes missing, you grab one from the shelf. When a 400ZR+ goes missing, you wait for a fabrication cycle to finish.
A rollout last year planned four parallel 400G links between two sites. Capacity planning assumed all four. During staging, one module failed. With a week's lead time, nobody would have noticed. With a four-month lead time, the system shipped with three links.
Available capacity 3 × 400G = 1.2 Tbps
Designed utilization 60% per link (240G avg)
Actual utilization 80% per link (320G avg)
Burst headroom 80G per link (was 160G)
Hash entropy 5-tuple: uneven distribution across 3 paths
ECMP redistributed traffic. Average utilization per link jumped from 60% to 80%. During peak hours, microbursts showed up as latency spikes. No alarms fired. The system looked healthy in the dashboard. Users noticed before monitoring did.
Three links instead of four also wrecked hash distribution. Elephant flows that consumed 15% of a single link at design capacity now ate 20%. Queue depths climbed. Tail latency followed.
The failed optic caused none of this. The assumption that you can replace a coherent pluggable in a week caused all of it.
Long lead times create a second problem. You validate optics against a specific system state: firmware version, platform behavior, DSP interaction. That state has a shelf life.
Week 4 Validation passes on FW v3.2.1
Week 8 Vendor ships FW v3.3.0 (security patch)
Week 12 Network team rolls FW v3.3.0 to production
Week 16 Optics arrive, deployed on FW v3.3.0 (never tested)
By the time optics arrive, the environment they were validated against no longer exists.
One deployment hit this exactly. Optics passed lab testing. In production, links came up, trained, ran for a while, then reset. Optical levels looked fine. Diagnostics showed nothing.
Root cause: the new firmware changed how the host walks through the CMIS state machine. Specifically, timing between ModuleReady and DataPathActivated shifted. The optics hadn't changed. The platform hadn't changed. The handshake between them had.
Two engineers spent three days on it. The fix was a single timeout adjustment. Finding it cost about $5,000 in loaded engineering time.
Standard spare strategy assumes you can replenish in days. That math falls apart with 16-week lead times.
Annual failure rate ~2% (industry average for pluggables)
Expected failures/year ~1
Short lead time 1–2 spares, replenish in days
Long lead time 4–6 spares needed (cover 16+ weeks)
Capital tied up $20k–$60k sitting on a shelf
Or you skip the spares, a module fails, and you're buying from the secondary market at 2–3× list price. No warranty. Uncertain provenance. Additional validation before you can trust it in production.
Teams that don't get burned by this run procurement and validation on separate tracks.
Track 2: Validation Keep testing with available units
Track 3: FW baseline Pin firmware version, defer upgrades until post-deploy
Track 4: Spare buffer Order 10–15% extra for spares + DOA
You order at design freeze, not after validation completes. You pin your firmware version through the deployment window. You budget for 10–15% extra modules because some will arrive dead and replacements take another 16 weeks.
Lead time shapes how your design behaves in production. Treat it like any other constraint in the link budget. Because it is one.